By Sidney Taiko Sheehan
AI and GAAIN – a game-changer in Alzheimer’s research (Image: Jim Stanis, USC Stevens INI)
For more than a decade, the promise of big data has transformed the way we problem solve. Advances in computational power, mathematical applications, and the sheer volume of data available have led to countless innovations in scientific research and medicine. And yet, there are significant challenges that can leave specialists siloed and stagnant in aspects of their work. Issues like lack of training, difficulty replicating findings, privacy concerns, and collaboration obstacles all stand in the way of using big data to find solutions to humanity’s biggest problems, notably in medicine.
The Keck School of Medicine of USC’s Mark and Mary Stevens Neuroimaging and Informatics Institute (Stevens INI) houses a multidisciplinary collaborative of experts in neuroimaging, data science, radiology, engineering, who are committed to removing obstacles that get in the way of big data’s promise, particularly in diseases affecting the brain. In 2015, the Stevens INI partnered with the Alzheimer’s Association to create the Global Alzheimer’s Association Interactive Network (GAAIN). The first of its kind, GAAIN is a federated network connecting independently operated Alzheimer’s disease and dementia-related data repositories from around the world. GAAIN was created to address the challenges of making data available and accessible while supporting and connecting researchers worldwide to accelerate the development of Alzheimer’s disease prevention and treatments.

The GAAIN team, (L-R) Ioannis Pappas, PhD, Assistant Professor, Karen Crawford, MIS Manager, Arthur W. Toga, PhD, Director, Sidney Taiko Sheehan, Communications Manager, Cally Xiao, PhD, Project Specialist, Scott Neu, PhD, Assistant Professor
Notably, researchers are using GAAIN for work like analyzing sex risk factors for Alzheimer’s disease and even analyzing how social determinants—like health care access, living environment, and education—are highly related to several indicators of brain health, including AD and other dementias. Researchers interested in examining health disparities among differing racial and ethnic groups, for example, have even more challenges finding the diverse cohorts they need for their studies. Finding and accessing this data can be incredibly time-consuming and laborious. By taking a closer look at the many challenges of this research, the utility of GAAIN becomes evident.
Sociology of data sharing
Why data sharing? Instead of “siloed” studies, bringing big data together allows for accelerated research in Alzheimer’s disease. For example, looking at rare neuroprotective mutations or developing a drug requires significant amounts of data to potentially reveal statistical significance. With GAAIN, researchers can pool data from different studies, thus increasing their sample size and the statistical power of their study.
Data owners are required to make data available (e.g., based on NIH grant guidelines), but many data owners do not want to merely hand over the data they spent resources and time to collect. GAAIN allows data owners (GAAIN Data Partners) to join a data sharing network using a fully federated and voluntary system. Specifically, GAAIN Data Partners:
- continue to manage their own data and the data is not centrally stored but rather accessed remotely from the data owners’ site
- experience minimal disruption to the data owners’ infrastructure
- can leave the network at any point
“When researchers become Data Partners, they are bringing together data from different modalities, such as genetic, imaging, and cognitive measures. GAAIN allows users to discover existing data sets and interesting trends, potentially leading to new treatments and cures,” said Stevens INI and GAAIN Director Dr. Arthur W. Toga. “Without this kind of active participation, big data loses its power to accelerate Alzheimer’s disease research.”
Training
Strong skills in digital data, informatics, machine learning, and programming are often required to perform sophisticated analysis. Users do not need to be experts in these fields to use GAAIN. The GAAIN Cohort Scout lets researchers search through thousands of data attributes collected by GAAIN Data Partners and allows users to build, save and share cohorts. The GAAIN Interrogator allows researchers to visually explore data attributes and graphs showing the distribution of data values, dynamically define cohorts and visually explore the differences between them and run preliminary analyses using custom variables and cohorts. Together, the GAAIN Cohort Scout and Interrogator drastically simplify the process of data accumulation and analysis.
Replication
A major challenge of data-driven approaches is to ensure that the findings can be replicated. When a research study uses GAAIN data, it allows other users to access the same data and conduct their own analyses with the hope of replicating the findings reported in the initial study. In addition, using GAAIN data incentivizes researchers to adhere to higher standards of research practice for the benefit of the entire scientific community.
Dissemination
The dissemination and communication of the knowledge gained from scientific studies are vital. When data owners become GAAIN Data Partners, they are actively contributing to the platform and the scientific community. The main goal of GAAIN is to bring together as much data as possible to allow users across the globe to unite in the process of discovery. Findings build upon each other, and incremental progress can be expedited when an all-hands-on-deck approach is adopted to address scientific challenges that no individual or single team can hope to overcome alone.
Safety, privacy, and interoperability
Although data increasingly exist in digital formats and provide remarkable opportunities for knowledge generation, obstacles still abound in collecting data from various sources. Some data owners, independent of privacy concerns, view data as assets to be hoarded rather than shared. Using the federated system, GAAIN does not centrally store the Data Partners’ data. To show the data in the GAAIN Interrogator, the data is remotely projected from the Data Partners’ sites. Communication between the Data Partners’ sites and GAAIN is performed securely, and data cannot be downloaded from GAAIN without the Data Partners’ approval. In addition, it is not possible to trace individual subjects using GAAIN’s Interrogator or to infer subject identities; identifying information such as names and addresses are also requested to be removed from the data sets before connecting to GAAIN. Regarding interoperability – the basic ability of different computerized products or systems to readily connect and exchange information with one another – GAAIN easily collects data from different data sources and can be integrated with other data platforms that potentially store different data modalities.

GAAIN architecture (Image: USC Stevens INI)
Collaboration
Finally, and perhaps most importantly, the rise of big data requires new collaboration for clinical research. Advances in medicine are likely to derive from work with mathematicians, statisticians, and computer scientists. The GAAIN platform unites a diverse and geographically distributed network of Data Partners and users within a federated data platform designed to foster cohort discovery, collaboration, and sharing. Open access data discovery brings together researchers from many complementary and adjacent disciplines, who might not otherwise have the opportunity to collaborate and further each other’s work. In scientific and medical discovery, it takes a village. GAAIN is working to build that community and to advance the democratization of scientific research.
GAAIN in action
Using data sets from the National Alzheimer’s Coordinating Center (NACC), the Alzheimer’s Disease Neuroimaging Initiative (ADNI), and the Texas Alzheimer’s Research and Care Consortium (TARCC), the GAAIN team used GAAIN’s Cohort Scout to establish non-Hispanic white (NHW) and Hispanic cohorts based on clinical dementia ratings (CDR). The CDR is a global rating scale for staging patients diagnosed with dementia:
- 0 = Normal
- 0.5 = Very Mild Dementia or Questionable Cognitive Impairment
- 1 = Mild Dementia
- 2 = Moderate Dementia
- 3 = Severe Dementia
One risk factor for developing Alzheimer’s disease (AD) is the APOE gene coding for the apolipoprotein E protein (apoE). Humans have three alleles of the APOE gene: ε2, ε3, and ε4. Carrying the ε4 allele is an AD risk factor while carrying the ε2 allele is protective. ApoE plays a pivotal role in the development, maintenance, and repair of the central nervous system, and regulates multiple critical signaling pathways. This analysis examines the presence of the APOE4 allele versus the most common genotype APOE3/3, as well as a history of hypertension versus no hypertension, as risk factors compared between Hispanic and NHW cohorts.
The GAAIN team then performed logistic regression using the Interrogator to find that Hispanic subjects with one or two APOE4 alleles were significantly less likely than NHW subjects with one or two APOE4 alleles to be diagnosed with questionable cognitive impairment or worse (CDR 0.5 or higher). Also, Hispanic subjects and NHW subjects with current or a history of hypertension have similar risks to be diagnosed with questionable cognitive impairment or worse. With these findings, the GAAIN team is now conducting a full secondary analysis with additional data sets and comparing APOE4, APOE2, hypertension, stroke, and depression risk factors for mild cognitive impairment and Alzheimer’s disease between Hispanic and NHW subjects.
“This analysis suggests that well-studied risk factors for Alzheimer’s disease and dementia differ in severity levels between ethnicities, which could be due to biological, cultural, or socioeconomical reasons. We aim to discern some of these differences with our full analysis, bringing attention to underrepresented populations in Alzheimer’s disease research,” said GAAIN Project Specialist Dr. Cally Xiao.
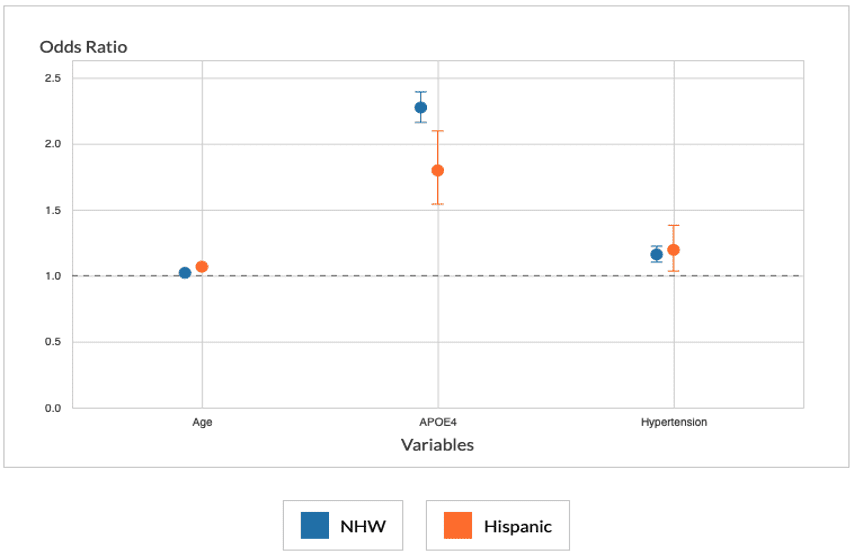
Logistic regression using the GAAIN Interrogator (Photo credit: USC Stevens INI)
“The power of GAAIN lies in its accessibility. We make it simple and safe to become a Data Partner. We also make the analysis and discovery tools easy to use to empower users from different disciplines and of various skill sets to perform their analyses. We take exceptional care to make accessible data that helps address health disparities, like the analysis we are working on now,” noted GAAIN team member Dr. Ioannis Pappas. “Our challenge now is to get the word out. The more researchers who share data and the more users who use GAAIN for their research, the further we move on the path of discovery and treatment.”
The GAAIN team is eager to answer any questions, provide tutorials, and to even partner on or assist with research projects. They can be reached at info@gaain.org.